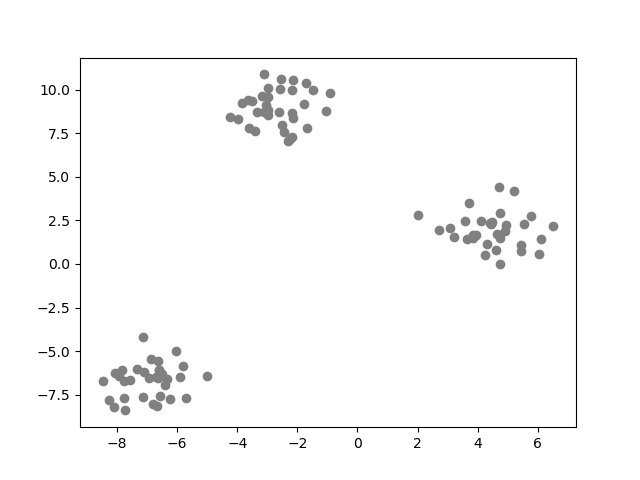
クラスタリングは教師なし学習の一つ。データに着目し、隠れた構造や知見を発見するためのモデルを構築すること。(教師あり学習では、目的変数と説明変数の関係を表現するモデルを構築した。)取扱うデータの特徴の把握、探索的分析の初期段階で採用されることがある。
クラスタリングで有名な、手法、k-means法を試します。
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# サンプルデータを生成
X, _ = make_blobs(random_state=42)
# グラフを描画
plt.scatter(X[:, 0], X[:, 1], color='gray')
plt.show()
# KMeansの初期化とクラスターを計算
kmeans = KMeans(init='random', n_clusters=3)
kmeans.fit(X)
# クラスターを予測
y = kmeans.predict(X)
# データを横に結合
data = pd.concat([pd.DataFrame(X[:, 0]), pd.DataFrame(
X[:, 1]), pd.DataFrame(y)], axis=1)
data.columns = ['a', 'b', 'cluster']
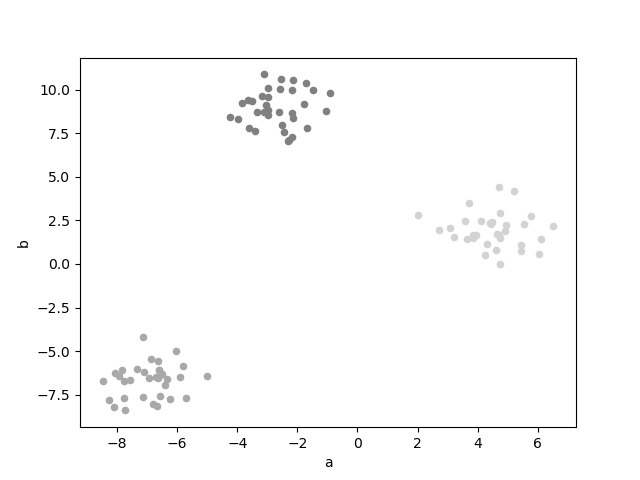
# クラスタリングの結果を表示
ax = None
colors = ['gray', 'lightgray', 'darkgray']
for i, d in data.groupby('cluster'):
ax = d.plot.scatter(
x='a', y='b', color=colors[i], ax=ax)
plt.show()
実行結果